Architecting microservices for effective development and deployment
(3 minute read)
Microservice architecture is very popular right now.
The last few places I've worked at have all embraced the micoservice philosophy of architecting systems whereby, instead of building one big monolothic service which does everything your backend needs to do, you instead build numerous services which are each responsible for just one aspect of your backend stack. These numerous services would then talk to each other as is needed to co-ordinate activity. You could then deploy and scale each service individually, and ensuring increased resources are focused only where they're most needed.
Typically you would then sit some sort of orchestrator in front of these micro-services to shield front-end apps from this architectural complexity - typically you might use a GraphQL server as the orchestration layer:
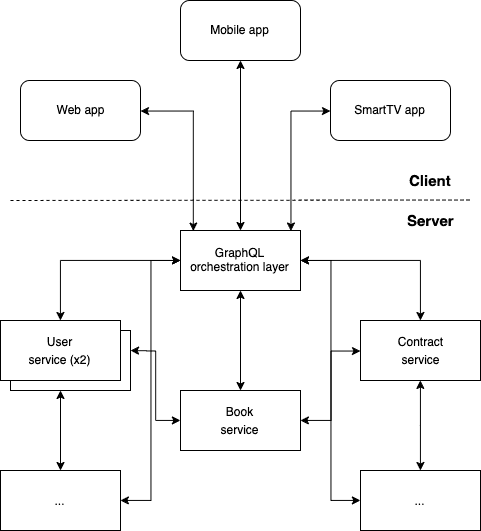
A consequence of splitting up backend code into multiple services is that, for ease of deployment, it then makes sense to split up the backend into multiple source repositories, typically one repository per service.
This then makes it slightly more cumbersome to share code between services. For instance, many of your micro services may speak to the same database and thus it would make sense for them to share the database connection layer code. The real pain comes when you update the shared code - you then need to update each and every one of the corresponding microservices which use that shared code.
Monorepos to the rescue
To ease this burden you may choose to use a monorepo structure. Essentially, all your services would sit in a single source repository but still be deployed separately. And Monorepos aren't just useful for backend services, they can be used to organize any collection of repositories that are closely related, e.g. Babel, Truffle, React.
But local development is no longer as straightforward...
Microservices enables us to build tightly focussed services that can be scaled individually. Monorepos enable us to do away with the dependency maintenance hell that would otherwise be present with a repo-per-service code structure. The remaining problem is that the local development story is no longer straightforward.
Ideally, when developing the frontend you should be able to run your entire backend stack locally. When your backend is a single monolithic service, you can just start an instance of that locally and...hey presto. If you have tonnes of micro services which all need to be run locally and need to be configured to talk to each other then it's not as easy. Monorepos don't help much here.
This is where something like Docker Compose comes to the rescue. Effectively, this enables us to start up pre-configured local instances of all the micro services with a single command:
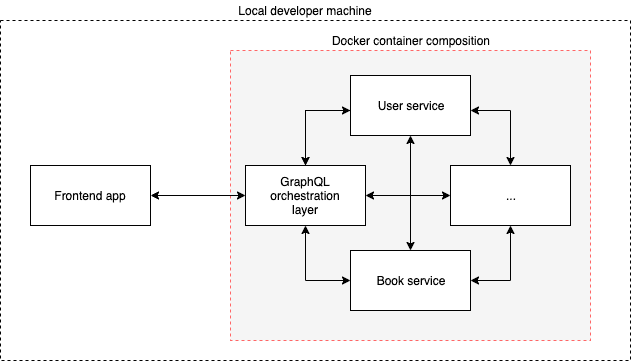
This makes it easy to start up your stack locally - and indeed, with the right tooling you could probably re-use your docker composition configuration for your actual deployed instances too.
And yet, your docker composition still isn't as easy as simply running a monolothic server.
How about we run the backend in monolith mode during development and in micro service mode during deployment?
The way this would work is that the backend server would have a running mode which gets configured at runtime via e.g. environment variables. The mode would determine which microservice the server would run as. If no mode is given then it would run all the microservices together as one giant monolithic service:
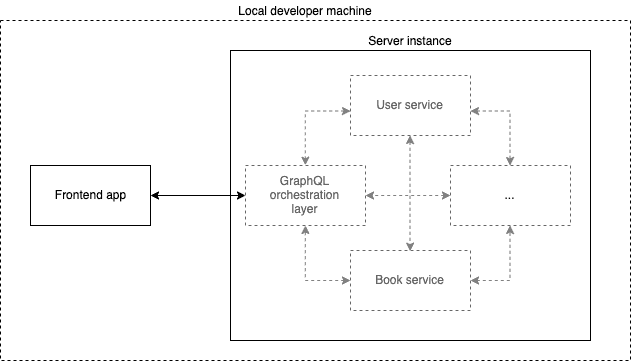
Obviously this would require refactoring the code within the server such that it could run in both modes. In monolithic mode you could still run each microservice as a child process, still listening on TCP ports so that you don't really have to change the way they talk to each other.
Or you could have the microservices talking to each other via straightforward method calls. Although this latter approach may seem less optimal, it makes more sense if you were to start off with your backend as a monolithic service and then progressively split things out into microservices as scaling issues required you to do so - and indeed, this is the approach I prefer.
Too often I've noticed engineering teams start off by splitting everything into microservices from the get-go such that the disadvantages of using microservices continued to outweigh the advantages gained from having them.
One other thing to note is that so far I haven't mentioned the other issues that come with microservices - such as network failures during inter-node communication. I would say a microservice architecture should be adopted as and when it makes sense to do so, i.e. when without it you wouldn't be able to scale. And if you do adopt microservices then ensure your local development story remains good.